Edge-Enhanced Attention GCN#
Edge-Enhanced Attention GNN definition#
We would now like to make use of edge features in our model, as we are for now completely missing out on these additional predictors.
To this end, we will use a custom approach inspired by the Exploiting Edge Features for Graph Neural Networks paper by Gong and Cheng, 2019.
We will adapt their Attention-based edge-enhanced neural network, termed EGNN(A), by redefining our Attention layer in the following way :
Compute the attention score \(\alpha^l_{ij}\) separately for each feature dimension \(p\) such that:
\(\alpha^l_{ijp} = f^l(X^{l-1}_i, X^{l-1}_j) \cdot E^{l-1}_{ijp}\)
In this, \(f^l\) is our previously used formula for the attention score (scalar) and \(X^{l-1}\) the output of the previous layer.
Here we simply compute the dot product with the edge feature matrix \(E\) of shape \(N \times N \times E_{feat}\).
Replace their proposed Double Stochastic Normalization with Group normalization for simplicity. We only have to ensure that the channel dimension corresponds to the edge features before normalizing; we will select the number of groups as a hyperparameter.
The obtained edge-enhanced attention score \(\alpha^l\) of shape \(N \times N \times E_{feat}\) is then used as the edge features \(E^l\) in the next layer as they suggest, i.e. \(E^{l} = \alpha^l\)
Then, not unlike multi-head attention (but with edge feature-specific heads instead of randomly initialized heads using the same input data), we concatenate on the edge feature dimension and feed the result to a fully-connected layer.
With this we obtain \(A^l\) of shape \(B \times N \times N\) :
\(A^l_{ij} = a_{ij} \vert \vert_{p=1}^P \alpha_{ijp}^l\)
where \(a\) is a learnable weight of shape \((E_{feat} N) \times N\) and \(\vert \vert\) is the concatenation operator.
Finally, the output is obtained by multiplying \(A^l\) with the support \(X^{l-1} W^l\) and applying the activation function:
\(X^l = \sigma (A^l X^{l-1} W^l)\)
We return \(X^l\) and \(E^l\), to be used by the next layer.
Validating our model#
In order to show that our proposed architecture is indeed an improvement, we perform some simple checks to make sure that our edge features and the Group normalization are actually helpful.
We will compare performance when :
Setting the edge feature matrix \(E^l\) to ones
Setting the edge-enhanced attention matrix \(A^l\) to ones before multiplying with the support
Removing the Group normalization
Results can be seen in Hyperparameter tuning for Edge-Enhanced Attention GCN.
Show code cell source
import warnings
import os
from sys import path
warnings.filterwarnings(
"ignore"
) # ignore warnings from missing deterministic implementation. These are strictly from wandb and do not affect the reproducibility of the actual runs.
os.environ[
"WANDB_NOTEBOOK_NAME"
] = "EdgeAttentionGCN.ipynb" # name the notebook for wandb tracking
path.append("../code")
Show code cell source
%load_ext autoreload
%autoreload 2
Show code cell source
import torch
from torch import nn
import numpy as np
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
import seaborn as sns
import model as m
import training as t
import utils
import logging
import sys
from utils import LOG as logger
logging.basicConfig(
format="%(message)s", level=logging.INFO, stream=sys.stdout
)
logger.setLevel(logging.INFO)
# logger.setLevel(logging.DEBUG)
t.WANDB_MODE = "disabled"
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dataloaders, dataset = t.create_dataloaders(
batch_size=20,
use_edge_features=True,
# train_split=0.5,
)
Length of train set: 131
Length of validation set: 28
Length of test set: 29
Training#
Model#
node_features = dataset.node_features.shape[2]
conv_dims = [256, 256, 128, 64]
model = m.EdgeAttentionGCN(
num_features=node_features,
conv_dims=conv_dims,
# fcn_layers=[128],
activation=nn.LeakyReLU(),
dropout=0.3,
pooling="max",
norm=nn.BatchNorm1d,
)
# utils._print_gradient_hook(model)
print(model)
Initialized model with 4 graph conv layers
Initialized model with 1 fully connected layers
EdgeAttentionGCN(
(convs_layers): ModuleList(
(0): EdgeConv(
(weight): Linear(in_features=7, out_features=256, bias=False)
(S): Linear(in_features=512, out_features=28, bias=False)
(edge_layer): Linear(in_features=112, out_features=28, bias=False)
(activation): LeakyReLU(negative_slope=0.01)
(att_activation): LeakyReLU(negative_slope=0.1)
(softmax): Softmax(dim=1)
(instance_norm): GroupNorm(4, 4, eps=1e-05, affine=True)
)
(1): EdgeConv(
(weight): Linear(in_features=256, out_features=256, bias=False)
(S): Linear(in_features=512, out_features=28, bias=False)
(edge_layer): Linear(in_features=112, out_features=28, bias=False)
(activation): LeakyReLU(negative_slope=0.01)
(att_activation): LeakyReLU(negative_slope=0.1)
(softmax): Softmax(dim=1)
(instance_norm): GroupNorm(4, 4, eps=1e-05, affine=True)
)
(2): EdgeConv(
(weight): Linear(in_features=256, out_features=128, bias=False)
(S): Linear(in_features=256, out_features=28, bias=False)
(edge_layer): Linear(in_features=112, out_features=28, bias=False)
(activation): LeakyReLU(negative_slope=0.01)
(att_activation): LeakyReLU(negative_slope=0.1)
(softmax): Softmax(dim=1)
(instance_norm): GroupNorm(4, 4, eps=1e-05, affine=True)
)
(3): EdgeConv(
(weight): Linear(in_features=128, out_features=64, bias=False)
(S): Linear(in_features=128, out_features=28, bias=False)
(edge_layer): Linear(in_features=112, out_features=28, bias=False)
(activation): Identity()
(att_activation): LeakyReLU(negative_slope=0.1)
(softmax): Softmax(dim=1)
(instance_norm): GroupNorm(4, 4, eps=1e-05, affine=True)
)
)
(batch_norms): ModuleList(
(0-1): 2 x BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Identity()
)
(fcn_layers): ModuleList(
(0): Linear(in_features=64, out_features=1, bias=True)
)
(dropout): Dropout(p=0.3, inplace=False)
(pooling): MaxPooling()
)
Training parameters#
epochs = 200 # this model converges much faster than the others
learning_rate = 1e-4 # it also benefits from a lower learning rate
model.to(DEVICE)
label_counts = dataset[:]["class_y"].unique(return_counts=True)[1]
pos_weight = label_counts[0] / label_counts[1]
loss_fn = nn.BCEWithLogitsLoss(pos_weight=torch.tensor(pos_weight))
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
history = {
"epoch": 0,
"loss": [],
"acc": [],
"val-roc": [],
"val-ap": [],
}
Training loop#
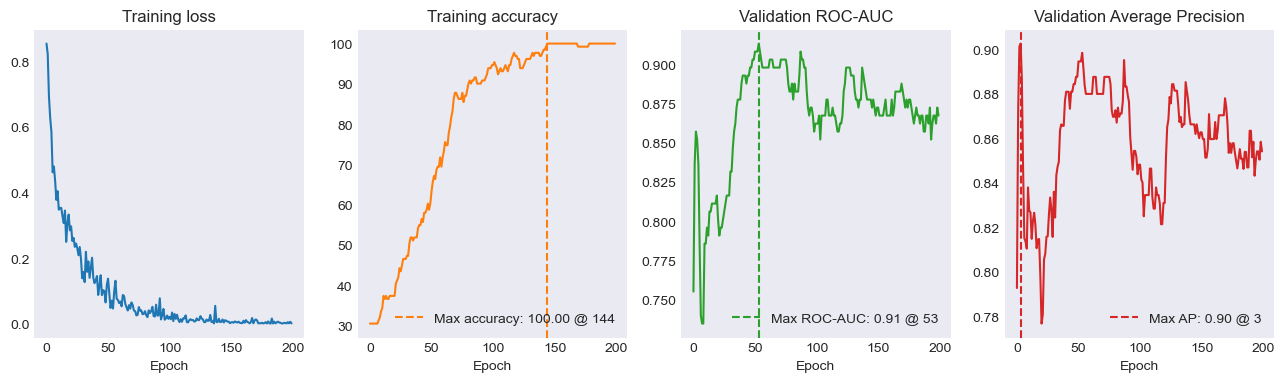
history = t.train_loop(
history=history,
train_dataloader=dataloaders[0],
val_dataloader=dataloaders[1],
model=model,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=epochs,
device=DEVICE,
use_scheduler=False,
test_dataloader=dataloaders[2],
use_edges=True,
)
Watching
Epoch 1/200:Epoch loss: 0.8547 - avg acc: 30.5% - val-roc: 0.7551 - val-ap: 0.7927 (0.5s/epoch)
Epoch 2/200:Epoch loss: 0.8229 - avg acc: 30.5% - val-roc: 0.8367 - val-ap: 0.8719 (0.2s/epoch)
Epoch 3/200:Epoch loss: 0.6942 - avg acc: 30.5% - val-roc: 0.8571 - val-ap: 0.9011 (0.2s/epoch)
Epoch 4/200:Epoch loss: 0.6281 - avg acc: 30.5% - val-roc: 0.8520 - val-ap: 0.9025 (0.2s/epoch)
Epoch 5/200:Epoch loss: 0.5854 - avg acc: 30.5% - val-roc: 0.8367 - val-ap: 0.8865 (0.2s/epoch)
Epoch 6/200:Epoch loss: 0.4621 - avg acc: 30.5% - val-roc: 0.7857 - val-ap: 0.8465 (0.2s/epoch)
Epoch 7/200:Epoch loss: 0.4798 - avg acc: 30.5% - val-roc: 0.7398 - val-ap: 0.8151 (0.2s/epoch)
Epoch 8/200:Epoch loss: 0.4373 - avg acc: 31.3% - val-roc: 0.7347 - val-ap: 0.8136 (0.2s/epoch)
Epoch 9/200:Epoch loss: 0.3781 - avg acc: 32.1% - val-roc: 0.7347 - val-ap: 0.8104 (0.2s/epoch)
Epoch 10/200:Epoch loss: 0.4047 - avg acc: 33.6% - val-roc: 0.7857 - val-ap: 0.8379 (0.2s/epoch)
Epoch 11/200:Epoch loss: 0.3483 - avg acc: 34.4% - val-roc: 0.7857 - val-ap: 0.8274 (0.2s/epoch)
Epoch 12/200:Epoch loss: 0.3539 - avg acc: 37.4% - val-roc: 0.7959 - val-ap: 0.8267 (0.2s/epoch)
Epoch 13/200:Epoch loss: 0.3533 - avg acc: 36.6% - val-roc: 0.7908 - val-ap: 0.8148 (0.2s/epoch)
Epoch 14/200:Epoch loss: 0.3279 - avg acc: 37.4% - val-roc: 0.8061 - val-ap: 0.8228 (0.2s/epoch)
Epoch 15/200:Epoch loss: 0.3074 - avg acc: 36.6% - val-roc: 0.8061 - val-ap: 0.8265 (0.2s/epoch)
Epoch 16/200:Epoch loss: 0.3455 - avg acc: 36.6% - val-roc: 0.8112 - val-ap: 0.8211 (0.2s/epoch)
Epoch 17/200:Epoch loss: 0.2500 - avg acc: 37.4% - val-roc: 0.8112 - val-ap: 0.8106 (0.2s/epoch)
Epoch 18/200:Epoch loss: 0.3071 - avg acc: 37.4% - val-roc: 0.8112 - val-ap: 0.8145 (0.2s/epoch)
Epoch 19/200:Epoch loss: 0.3333 - avg acc: 37.4% - val-roc: 0.8112 - val-ap: 0.8147 (0.2s/epoch)
Epoch 20/200:Epoch loss: 0.2852 - avg acc: 37.4% - val-roc: 0.8163 - val-ap: 0.7983 (0.2s/epoch)
Epoch 21/200:Epoch loss: 0.2973 - avg acc: 37.4% - val-roc: 0.8010 - val-ap: 0.7767 (0.2s/epoch)
Epoch 22/200:Epoch loss: 0.2527 - avg acc: 40.5% - val-roc: 0.7908 - val-ap: 0.7807 (0.2s/epoch)
Epoch 23/200:Epoch loss: 0.2623 - avg acc: 41.2% - val-roc: 0.7959 - val-ap: 0.8056 (0.2s/epoch)
Epoch 24/200:Epoch loss: 0.2349 - avg acc: 42.0% - val-roc: 0.7959 - val-ap: 0.8080 (0.2s/epoch)
Epoch 25/200:Epoch loss: 0.2452 - avg acc: 44.3% - val-roc: 0.8010 - val-ap: 0.8157 (0.2s/epoch)
Epoch 26/200:Epoch loss: 0.2307 - avg acc: 43.5% - val-roc: 0.8061 - val-ap: 0.8159 (0.2s/epoch)
Epoch 27/200:Epoch loss: 0.2093 - avg acc: 45.0% - val-roc: 0.8112 - val-ap: 0.8257 (0.2s/epoch)
Epoch 28/200:Epoch loss: 0.2342 - avg acc: 46.6% - val-roc: 0.8163 - val-ap: 0.8333 (0.2s/epoch)
Epoch 29/200:Epoch loss: 0.1984 - avg acc: 46.6% - val-roc: 0.8163 - val-ap: 0.8277 (0.2s/epoch)
Epoch 30/200:Epoch loss: 0.1390 - avg acc: 46.6% - val-roc: 0.8163 - val-ap: 0.8156 (0.2s/epoch)
Epoch 31/200:Epoch loss: 0.1583 - avg acc: 47.3% - val-roc: 0.8316 - val-ap: 0.8359 (0.2s/epoch)
Epoch 32/200:Epoch loss: 0.1273 - avg acc: 47.3% - val-roc: 0.8316 - val-ap: 0.8244 (0.2s/epoch)
Epoch 33/200:Epoch loss: 0.2196 - avg acc: 50.4% - val-roc: 0.8469 - val-ap: 0.8433 (0.2s/epoch)
Epoch 34/200:Epoch loss: 0.1588 - avg acc: 51.9% - val-roc: 0.8571 - val-ap: 0.8471 (0.2s/epoch)
Epoch 35/200:Epoch loss: 0.1904 - avg acc: 51.9% - val-roc: 0.8622 - val-ap: 0.8493 (0.3s/epoch)
Epoch 36/200:Epoch loss: 0.1403 - avg acc: 51.1% - val-roc: 0.8724 - val-ap: 0.8636 (0.2s/epoch)
Epoch 37/200:Epoch loss: 0.1701 - avg acc: 51.9% - val-roc: 0.8776 - val-ap: 0.8662 (0.2s/epoch)
Epoch 38/200:Epoch loss: 0.2017 - avg acc: 51.9% - val-roc: 0.8776 - val-ap: 0.8656 (0.2s/epoch)
Epoch 39/200:Epoch loss: 0.1411 - avg acc: 51.9% - val-roc: 0.8776 - val-ap: 0.8656 (0.2s/epoch)
Epoch 40/200:Epoch loss: 0.1241 - avg acc: 54.2% - val-roc: 0.8878 - val-ap: 0.8768 (0.2s/epoch)
Epoch 41/200:Epoch loss: 0.1325 - avg acc: 55.0% - val-roc: 0.8929 - val-ap: 0.8809 (0.2s/epoch)
Epoch 42/200:Epoch loss: 0.1458 - avg acc: 55.0% - val-roc: 0.8929 - val-ap: 0.8809 (0.2s/epoch)
Epoch 43/200:Epoch loss: 0.0882 - avg acc: 56.5% - val-roc: 0.8929 - val-ap: 0.8809 (0.2s/epoch)
Epoch 44/200:Epoch loss: 0.1151 - avg acc: 55.7% - val-roc: 0.8878 - val-ap: 0.8732 (0.2s/epoch)
Epoch 45/200:Epoch loss: 0.1482 - avg acc: 58.0% - val-roc: 0.8929 - val-ap: 0.8809 (0.2s/epoch)
Epoch 46/200:Epoch loss: 0.0878 - avg acc: 58.0% - val-roc: 0.8929 - val-ap: 0.8809 (0.2s/epoch)
Epoch 47/200:Epoch loss: 0.1028 - avg acc: 58.8% - val-roc: 0.8980 - val-ap: 0.8843 (0.2s/epoch)
Epoch 48/200:Epoch loss: 0.0999 - avg acc: 60.3% - val-roc: 0.8980 - val-ap: 0.8843 (0.2s/epoch)
Epoch 49/200:Epoch loss: 0.0654 - avg acc: 58.8% - val-roc: 0.9031 - val-ap: 0.8876 (0.2s/epoch)
Epoch 50/200:Epoch loss: 0.1199 - avg acc: 60.3% - val-roc: 0.9031 - val-ap: 0.8876 (0.2s/epoch)
Epoch 51/200:Epoch loss: 0.1378 - avg acc: 63.4% - val-roc: 0.9082 - val-ap: 0.8945 (0.2s/epoch)
Epoch 52/200:Epoch loss: 0.0923 - avg acc: 65.6% - val-roc: 0.9082 - val-ap: 0.8945 (0.2s/epoch)
Epoch 53/200:Epoch loss: 0.0485 - avg acc: 67.2% - val-roc: 0.9082 - val-ap: 0.8945 (0.2s/epoch)
Epoch 54/200:Epoch loss: 0.0706 - avg acc: 66.4% - val-roc: 0.9133 - val-ap: 0.8984 (0.2s/epoch)
Epoch 55/200:Epoch loss: 0.0468 - avg acc: 68.7% - val-roc: 0.9082 - val-ap: 0.8914 (0.2s/epoch)
Epoch 56/200:Epoch loss: 0.0991 - avg acc: 69.5% - val-roc: 0.9031 - val-ap: 0.8838 (0.2s/epoch)
Epoch 57/200:Epoch loss: 0.1314 - avg acc: 69.5% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 58/200:Epoch loss: 0.0765 - avg acc: 71.8% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 59/200:Epoch loss: 0.0730 - avg acc: 69.5% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 60/200:Epoch loss: 0.0632 - avg acc: 71.8% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 61/200:Epoch loss: 0.0682 - avg acc: 73.3% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 62/200:Epoch loss: 0.0533 - avg acc: 75.6% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 63/200:Epoch loss: 0.0880 - avg acc: 74.8% - val-roc: 0.9031 - val-ap: 0.8876 (0.2s/epoch)
Epoch 64/200:Epoch loss: 0.0847 - avg acc: 74.8% - val-roc: 0.9031 - val-ap: 0.8876 (0.2s/epoch)
Epoch 65/200:Epoch loss: 0.0609 - avg acc: 77.9% - val-roc: 0.9031 - val-ap: 0.8876 (0.2s/epoch)
Epoch 66/200:Epoch loss: 0.0503 - avg acc: 79.4% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 67/200:Epoch loss: 0.0408 - avg acc: 81.7% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 68/200:Epoch loss: 0.0571 - avg acc: 83.2% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 69/200:Epoch loss: 0.0463 - avg acc: 86.3% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 70/200:Epoch loss: 0.0654 - avg acc: 87.8% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 71/200:Epoch loss: 0.0577 - avg acc: 87.8% - val-roc: 0.8980 - val-ap: 0.8799 (0.2s/epoch)
Epoch 72/200:Epoch loss: 0.0408 - avg acc: 87.0% - val-roc: 0.9031 - val-ap: 0.8876 (0.2s/epoch)
Epoch 73/200:Epoch loss: 0.0389 - avg acc: 86.3% - val-roc: 0.9031 - val-ap: 0.8876 (0.2s/epoch)
Epoch 74/200:Epoch loss: 0.0258 - avg acc: 86.3% - val-roc: 0.9031 - val-ap: 0.8876 (0.2s/epoch)
Epoch 75/200:Epoch loss: 0.0276 - avg acc: 86.3% - val-roc: 0.9031 - val-ap: 0.8876 (0.2s/epoch)
Epoch 76/200:Epoch loss: 0.0512 - avg acc: 87.8% - val-roc: 0.9031 - val-ap: 0.8876 (0.2s/epoch)
Epoch 77/200:Epoch loss: 0.0405 - avg acc: 85.5% - val-roc: 0.8980 - val-ap: 0.8843 (0.2s/epoch)
Epoch 78/200:Epoch loss: 0.0409 - avg acc: 87.0% - val-roc: 0.8878 - val-ap: 0.8726 (0.2s/epoch)
Epoch 79/200:Epoch loss: 0.0296 - avg acc: 87.0% - val-roc: 0.8827 - val-ap: 0.8696 (0.2s/epoch)
Epoch 80/200:Epoch loss: 0.0304 - avg acc: 88.5% - val-roc: 0.8827 - val-ap: 0.8696 (0.2s/epoch)
Epoch 81/200:Epoch loss: 0.0387 - avg acc: 90.1% - val-roc: 0.8878 - val-ap: 0.8726 (0.2s/epoch)
Epoch 82/200:Epoch loss: 0.0263 - avg acc: 90.8% - val-roc: 0.8776 - val-ap: 0.8670 (0.2s/epoch)
Epoch 83/200:Epoch loss: 0.0204 - avg acc: 90.1% - val-roc: 0.8878 - val-ap: 0.8737 (0.2s/epoch)
Epoch 84/200:Epoch loss: 0.0411 - avg acc: 90.8% - val-roc: 0.8827 - val-ap: 0.8696 (0.2s/epoch)
Epoch 85/200:Epoch loss: 0.0329 - avg acc: 90.8% - val-roc: 0.8827 - val-ap: 0.8711 (0.2s/epoch)
Epoch 86/200:Epoch loss: 0.0386 - avg acc: 91.6% - val-roc: 0.8827 - val-ap: 0.8711 (0.2s/epoch)
Epoch 87/200:Epoch loss: 0.0520 - avg acc: 91.6% - val-roc: 0.8929 - val-ap: 0.8766 (0.2s/epoch)
Epoch 88/200:Epoch loss: 0.0240 - avg acc: 90.1% - val-roc: 0.9082 - val-ap: 0.8951 (0.2s/epoch)
Epoch 89/200:Epoch loss: 0.0224 - avg acc: 90.1% - val-roc: 0.9031 - val-ap: 0.8832 (0.2s/epoch)
Epoch 90/200:Epoch loss: 0.0585 - avg acc: 90.1% - val-roc: 0.9031 - val-ap: 0.8832 (0.2s/epoch)
Epoch 91/200:Epoch loss: 0.0255 - avg acc: 90.1% - val-roc: 0.8980 - val-ap: 0.8793 (0.2s/epoch)
Epoch 92/200:Epoch loss: 0.0253 - avg acc: 90.8% - val-roc: 0.8980 - val-ap: 0.8763 (0.2s/epoch)
Epoch 93/200:Epoch loss: 0.0780 - avg acc: 90.8% - val-roc: 0.8827 - val-ap: 0.8606 (0.2s/epoch)
Epoch 94/200:Epoch loss: 0.0135 - avg acc: 90.8% - val-roc: 0.8724 - val-ap: 0.8529 (0.2s/epoch)
Epoch 95/200:Epoch loss: 0.0269 - avg acc: 91.6% - val-roc: 0.8673 - val-ap: 0.8458 (0.2s/epoch)
Epoch 96/200:Epoch loss: 0.0454 - avg acc: 92.4% - val-roc: 0.8724 - val-ap: 0.8543 (0.2s/epoch)
Epoch 97/200:Epoch loss: 0.0126 - avg acc: 93.9% - val-roc: 0.8724 - val-ap: 0.8543 (0.2s/epoch)
Epoch 98/200:Epoch loss: 0.0169 - avg acc: 93.9% - val-roc: 0.8673 - val-ap: 0.8517 (0.2s/epoch)
Epoch 99/200:Epoch loss: 0.0254 - avg acc: 93.9% - val-roc: 0.8571 - val-ap: 0.8438 (0.2s/epoch)
Epoch 100/200:Epoch loss: 0.0154 - avg acc: 94.7% - val-roc: 0.8622 - val-ap: 0.8481 (0.2s/epoch)
Epoch 101/200:Epoch loss: 0.0211 - avg acc: 94.7% - val-roc: 0.8622 - val-ap: 0.8481 (0.2s/epoch)
Epoch 102/200:Epoch loss: 0.0142 - avg acc: 95.4% - val-roc: 0.8622 - val-ap: 0.8415 (0.2s/epoch)
Epoch 103/200:Epoch loss: 0.0343 - avg acc: 94.7% - val-roc: 0.8673 - val-ap: 0.8400 (0.2s/epoch)
Epoch 104/200:Epoch loss: 0.0085 - avg acc: 93.9% - val-roc: 0.8520 - val-ap: 0.8249 (0.2s/epoch)
Epoch 105/200:Epoch loss: 0.0303 - avg acc: 92.4% - val-roc: 0.8673 - val-ap: 0.8344 (0.2s/epoch)
Epoch 106/200:Epoch loss: 0.0153 - avg acc: 93.1% - val-roc: 0.8673 - val-ap: 0.8344 (0.2s/epoch)
Epoch 107/200:Epoch loss: 0.0279 - avg acc: 93.9% - val-roc: 0.8673 - val-ap: 0.8344 (0.2s/epoch)
Epoch 108/200:Epoch loss: 0.0131 - avg acc: 93.1% - val-roc: 0.8673 - val-ap: 0.8344 (0.2s/epoch)
Epoch 109/200:Epoch loss: 0.0053 - avg acc: 93.1% - val-roc: 0.8776 - val-ap: 0.8464 (0.2s/epoch)
Epoch 110/200:Epoch loss: 0.0144 - avg acc: 93.9% - val-roc: 0.8776 - val-ap: 0.8464 (0.2s/epoch)
Epoch 111/200:Epoch loss: 0.0063 - avg acc: 94.7% - val-roc: 0.8673 - val-ap: 0.8335 (0.2s/epoch)
Epoch 112/200:Epoch loss: 0.0169 - avg acc: 93.9% - val-roc: 0.8673 - val-ap: 0.8283 (0.2s/epoch)
Epoch 113/200:Epoch loss: 0.0164 - avg acc: 93.1% - val-roc: 0.8673 - val-ap: 0.8283 (0.2s/epoch)
Epoch 114/200:Epoch loss: 0.0258 - avg acc: 94.7% - val-roc: 0.8724 - val-ap: 0.8379 (0.2s/epoch)
Epoch 115/200:Epoch loss: 0.0053 - avg acc: 94.7% - val-roc: 0.8673 - val-ap: 0.8344 (0.2s/epoch)
Epoch 116/200:Epoch loss: 0.0048 - avg acc: 96.2% - val-roc: 0.8673 - val-ap: 0.8344 (0.2s/epoch)
Epoch 117/200:Epoch loss: 0.0114 - avg acc: 96.9% - val-roc: 0.8622 - val-ap: 0.8309 (0.2s/epoch)
Epoch 118/200:Epoch loss: 0.0141 - avg acc: 97.7% - val-roc: 0.8571 - val-ap: 0.8213 (0.2s/epoch)
Epoch 119/200:Epoch loss: 0.0111 - avg acc: 96.9% - val-roc: 0.8571 - val-ap: 0.8213 (0.2s/epoch)
Epoch 120/200:Epoch loss: 0.0118 - avg acc: 96.9% - val-roc: 0.8622 - val-ap: 0.8309 (0.2s/epoch)
Epoch 121/200:Epoch loss: 0.0071 - avg acc: 96.2% - val-roc: 0.8622 - val-ap: 0.8309 (0.2s/epoch)
Epoch 122/200:Epoch loss: 0.0080 - avg acc: 96.2% - val-roc: 0.8673 - val-ap: 0.8507 (0.2s/epoch)
Epoch 123/200:Epoch loss: 0.0166 - avg acc: 93.9% - val-roc: 0.8827 - val-ap: 0.8649 (0.2s/epoch)
Epoch 124/200:Epoch loss: 0.0119 - avg acc: 93.9% - val-roc: 0.8878 - val-ap: 0.8683 (0.2s/epoch)
Epoch 125/200:Epoch loss: 0.0115 - avg acc: 93.9% - val-roc: 0.8980 - val-ap: 0.8785 (0.2s/epoch)
Epoch 126/200:Epoch loss: 0.0236 - avg acc: 94.7% - val-roc: 0.8980 - val-ap: 0.8756 (0.2s/epoch)
Epoch 127/200:Epoch loss: 0.0164 - avg acc: 95.4% - val-roc: 0.8980 - val-ap: 0.8843 (0.2s/epoch)
Epoch 128/200:Epoch loss: 0.0138 - avg acc: 96.2% - val-roc: 0.8980 - val-ap: 0.8843 (0.3s/epoch)
Epoch 129/200:Epoch loss: 0.0053 - avg acc: 96.2% - val-roc: 0.8929 - val-ap: 0.8814 (0.2s/epoch)
Epoch 130/200:Epoch loss: 0.0055 - avg acc: 96.2% - val-roc: 0.8929 - val-ap: 0.8814 (0.2s/epoch)
Epoch 131/200:Epoch loss: 0.0133 - avg acc: 96.2% - val-roc: 0.8929 - val-ap: 0.8814 (0.2s/epoch)
Epoch 132/200:Epoch loss: 0.0093 - avg acc: 96.9% - val-roc: 0.8827 - val-ap: 0.8749 (0.2s/epoch)
Epoch 133/200:Epoch loss: 0.0099 - avg acc: 97.7% - val-roc: 0.8776 - val-ap: 0.8673 (0.2s/epoch)
Epoch 134/200:Epoch loss: 0.0272 - avg acc: 96.9% - val-roc: 0.8776 - val-ap: 0.8695 (0.2s/epoch)
Epoch 135/200:Epoch loss: 0.0057 - avg acc: 97.7% - val-roc: 0.8724 - val-ap: 0.8650 (0.2s/epoch)
Epoch 136/200:Epoch loss: 0.0075 - avg acc: 97.7% - val-roc: 0.8776 - val-ap: 0.8662 (0.2s/epoch)
Epoch 137/200:Epoch loss: 0.0014 - avg acc: 97.7% - val-roc: 0.8776 - val-ap: 0.8662 (0.2s/epoch)
Epoch 138/200:Epoch loss: 0.0549 - avg acc: 97.7% - val-roc: 0.8980 - val-ap: 0.8852 (0.2s/epoch)
Epoch 139/200:Epoch loss: 0.0054 - avg acc: 96.9% - val-roc: 0.8929 - val-ap: 0.8814 (0.2s/epoch)
Epoch 140/200:Epoch loss: 0.0057 - avg acc: 96.9% - val-roc: 0.8878 - val-ap: 0.8773 (0.2s/epoch)
Epoch 141/200:Epoch loss: 0.0154 - avg acc: 97.7% - val-roc: 0.8827 - val-ap: 0.8703 (0.2s/epoch)
Epoch 142/200:Epoch loss: 0.0053 - avg acc: 98.5% - val-roc: 0.8776 - val-ap: 0.8662 (0.2s/epoch)
Epoch 143/200:Epoch loss: 0.0063 - avg acc: 98.5% - val-roc: 0.8776 - val-ap: 0.8662 (0.2s/epoch)
Epoch 144/200:Epoch loss: 0.0134 - avg acc: 99.2% - val-roc: 0.8776 - val-ap: 0.8662 (0.2s/epoch)
Epoch 145/200:Epoch loss: 0.0041 - avg acc: 100.0% - val-roc: 0.8776 - val-ap: 0.8662 (0.2s/epoch)
Epoch 146/200:Epoch loss: 0.0113 - avg acc: 100.0% - val-roc: 0.8724 - val-ap: 0.8619 (0.2s/epoch)
Epoch 147/200:Epoch loss: 0.0092 - avg acc: 100.0% - val-roc: 0.8776 - val-ap: 0.8662 (0.2s/epoch)
Epoch 148/200:Epoch loss: 0.0070 - avg acc: 100.0% - val-roc: 0.8724 - val-ap: 0.8626 (0.2s/epoch)
Epoch 149/200:Epoch loss: 0.0064 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8600 (0.2s/epoch)
Epoch 150/200:Epoch loss: 0.0022 - avg acc: 100.0% - val-roc: 0.8724 - val-ap: 0.8626 (0.2s/epoch)
Epoch 151/200:Epoch loss: 0.0045 - avg acc: 100.0% - val-roc: 0.8724 - val-ap: 0.8626 (0.2s/epoch)
Epoch 152/200:Epoch loss: 0.0055 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8596 (0.2s/epoch)
Epoch 153/200:Epoch loss: 0.0035 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8596 (0.2s/epoch)
Epoch 154/200:Epoch loss: 0.0074 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8513 (0.2s/epoch)
Epoch 155/200:Epoch loss: 0.0055 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8513 (0.2s/epoch)
Epoch 156/200:Epoch loss: 0.0040 - avg acc: 100.0% - val-roc: 0.8724 - val-ap: 0.8554 (0.2s/epoch)
Epoch 157/200:Epoch loss: 0.0067 - avg acc: 100.0% - val-roc: 0.8776 - val-ap: 0.8708 (0.2s/epoch)
Epoch 158/200:Epoch loss: 0.0032 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8596 (0.2s/epoch)
Epoch 159/200:Epoch loss: 0.0027 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8596 (0.2s/epoch)
Epoch 160/200:Epoch loss: 0.0021 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8596 (0.2s/epoch)
Epoch 161/200:Epoch loss: 0.0096 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8596 (0.2s/epoch)
Epoch 162/200:Epoch loss: 0.0036 - avg acc: 100.0% - val-roc: 0.8776 - val-ap: 0.8673 (0.2s/epoch)
Epoch 163/200:Epoch loss: 0.0114 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8596 (0.2s/epoch)
Epoch 164/200:Epoch loss: 0.0059 - avg acc: 100.0% - val-roc: 0.8724 - val-ap: 0.8632 (0.2s/epoch)
Epoch 165/200:Epoch loss: 0.0044 - avg acc: 100.0% - val-roc: 0.8827 - val-ap: 0.8703 (0.2s/epoch)
Epoch 166/200:Epoch loss: 0.0016 - avg acc: 100.0% - val-roc: 0.8827 - val-ap: 0.8703 (0.2s/epoch)
Epoch 167/200:Epoch loss: 0.0060 - avg acc: 100.0% - val-roc: 0.8827 - val-ap: 0.8703 (0.2s/epoch)
Epoch 168/200:Epoch loss: 0.0179 - avg acc: 100.0% - val-roc: 0.8827 - val-ap: 0.8703 (0.2s/epoch)
Epoch 169/200:Epoch loss: 0.0016 - avg acc: 100.0% - val-roc: 0.8827 - val-ap: 0.8703 (0.2s/epoch)
Epoch 170/200:Epoch loss: 0.0103 - avg acc: 99.2% - val-roc: 0.8878 - val-ap: 0.8779 (0.2s/epoch)
Epoch 171/200:Epoch loss: 0.0135 - avg acc: 99.2% - val-roc: 0.8827 - val-ap: 0.8739 (0.2s/epoch)
Epoch 172/200:Epoch loss: 0.0105 - avg acc: 99.2% - val-roc: 0.8776 - val-ap: 0.8662 (0.2s/epoch)
Epoch 173/200:Epoch loss: 0.0017 - avg acc: 99.2% - val-roc: 0.8724 - val-ap: 0.8534 (0.2s/epoch)
Epoch 174/200:Epoch loss: 0.0020 - avg acc: 99.2% - val-roc: 0.8776 - val-ap: 0.8577 (0.2s/epoch)
Epoch 175/200:Epoch loss: 0.0020 - avg acc: 99.2% - val-roc: 0.8724 - val-ap: 0.8534 (0.2s/epoch)
Epoch 176/200:Epoch loss: 0.0034 - avg acc: 99.2% - val-roc: 0.8776 - val-ap: 0.8577 (0.2s/epoch)
Epoch 177/200:Epoch loss: 0.0012 - avg acc: 99.2% - val-roc: 0.8776 - val-ap: 0.8577 (0.2s/epoch)
Epoch 178/200:Epoch loss: 0.0024 - avg acc: 99.2% - val-roc: 0.8724 - val-ap: 0.8534 (0.2s/epoch)
Epoch 179/200:Epoch loss: 0.0052 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8500 (0.2s/epoch)
Epoch 180/200:Epoch loss: 0.0011 - avg acc: 100.0% - val-roc: 0.8622 - val-ap: 0.8464 (0.2s/epoch)
Epoch 181/200:Epoch loss: 0.0075 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8508 (0.2s/epoch)
Epoch 182/200:Epoch loss: 0.0020 - avg acc: 100.0% - val-roc: 0.8724 - val-ap: 0.8551 (0.2s/epoch)
Epoch 183/200:Epoch loss: 0.0009 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8508 (0.2s/epoch)
Epoch 184/200:Epoch loss: 0.0163 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8508 (0.2s/epoch)
Epoch 185/200:Epoch loss: 0.0012 - avg acc: 100.0% - val-roc: 0.8622 - val-ap: 0.8462 (0.2s/epoch)
Epoch 186/200:Epoch loss: 0.0066 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8538 (0.2s/epoch)
Epoch 187/200:Epoch loss: 0.0015 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8538 (0.2s/epoch)
Epoch 188/200:Epoch loss: 0.0047 - avg acc: 100.0% - val-roc: 0.8571 - val-ap: 0.8469 (0.2s/epoch)
Epoch 189/200:Epoch loss: 0.0067 - avg acc: 100.0% - val-roc: 0.8571 - val-ap: 0.8469 (0.2s/epoch)
Epoch 190/200:Epoch loss: 0.0039 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8633 (0.2s/epoch)
Epoch 191/200:Epoch loss: 0.0033 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8633 (0.2s/epoch)
Epoch 192/200:Epoch loss: 0.0013 - avg acc: 100.0% - val-roc: 0.8622 - val-ap: 0.8514 (0.2s/epoch)
Epoch 193/200:Epoch loss: 0.0013 - avg acc: 100.0% - val-roc: 0.8724 - val-ap: 0.8584 (0.2s/epoch)
Epoch 194/200:Epoch loss: 0.0033 - avg acc: 100.0% - val-roc: 0.8520 - val-ap: 0.8431 (0.2s/epoch)
Epoch 195/200:Epoch loss: 0.0023 - avg acc: 100.0% - val-roc: 0.8622 - val-ap: 0.8503 (0.2s/epoch)
Epoch 196/200:Epoch loss: 0.0016 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8541 (0.2s/epoch)
Epoch 197/200:Epoch loss: 0.0054 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8541 (0.2s/epoch)
Epoch 198/200:Epoch loss: 0.0017 - avg acc: 100.0% - val-roc: 0.8622 - val-ap: 0.8503 (0.2s/epoch)
Epoch 199/200:Epoch loss: 0.0064 - avg acc: 100.0% - val-roc: 0.8724 - val-ap: 0.8584 (0.2s/epoch)
Epoch 200/200:Epoch loss: 0.0014 - avg acc: 100.0% - val-roc: 0.8673 - val-ap: 0.8541 (0.2s/epoch)
Done!
Test ROC: 0.9111 - Test AP: 0.9649
Plots of training history#
utils.plot_history(history)
Validation on unseen data#
test_roc, test_ap, preds, ys = t.test(
dataloaders[2].dataset, model, return_preds=True
)
print(f"Test ROC-AUC: {test_roc:.4f}")
print(f"Test AP: {test_ap:.4f}")
# Plot the ROC curve
fig = t.plot_roc_curve(dataloaders[2].dataset, model)
print(
f"Number of correct positive predictions on test set: {torch.sum((preds > 0.5) & (ys == 1)).numpy()} out of {torch.sum(ys == 1).numpy()}"
)
print(
f"Number of correct negative predictions on test set: {torch.sum((preds < 0.5) & (ys == 0)).numpy()} out of {torch.sum(ys == 0).numpy()}"
)
Test ROC-AUC: 0.9111
Test AP: 0.9649
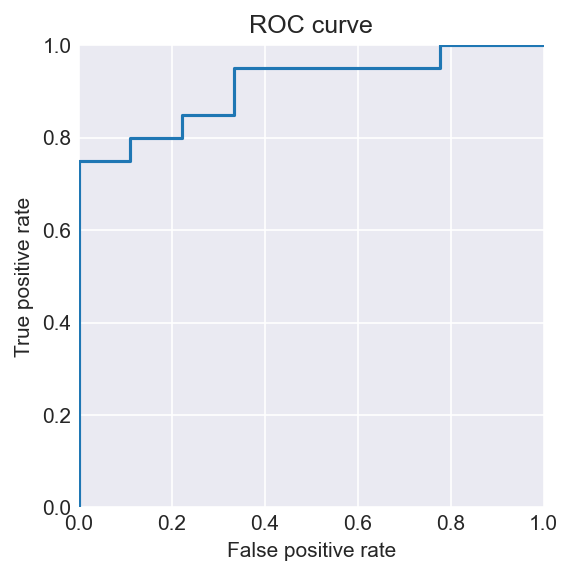
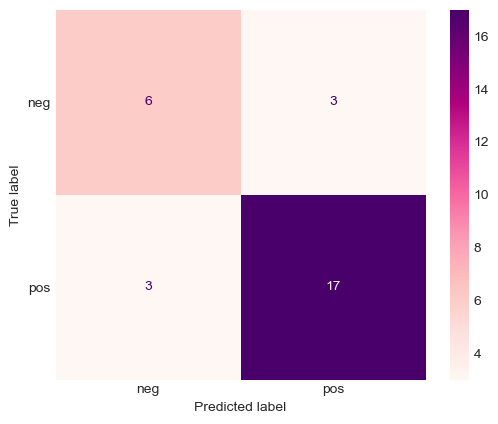
Number of correct positive predictions on test set: 17 out of 20
Number of correct negative predictions on test set: 6 out of 9
utils.show_preds_distribution(preds, ys)
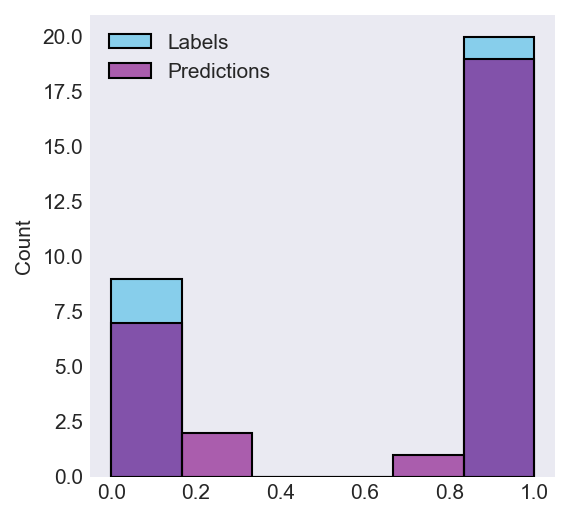
This plot shows the distribution of the labels and predictions;
predictions are overlayed on top of the labels,
showing whether they are missing or surnumerous.
The labels are 20 positive and 9 negative.
The predictions are 20 positive and 9 negative.
utils.plot_confusion_matrix(preds, ys)
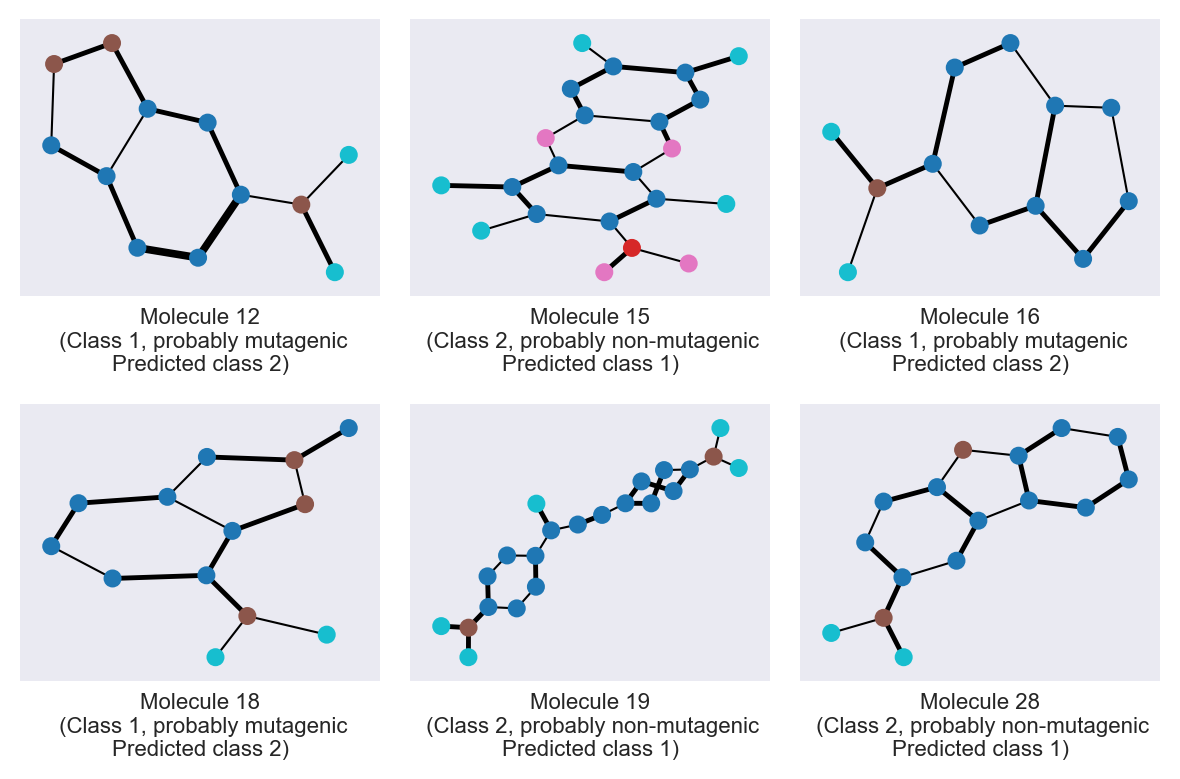
mislabeled = utils.find_mislabeled_molecules(preds, ys.numpy().astype(int))
print(f"{len(mislabeled)} mislabeled molecules")
mols = []
for id_mol in mislabeled:
mols.append(dataloaders[2].dataset[id_mol])
thresh_preds = np.where(preds > 0.5, 1, 0)[mislabeled]
utils.draw_molecule_from_dict(
mols[:6],
preds=thresh_preds,
mol_ids=mislabeled,
n_cols=3,
n_rows=2,
figsize=(6, 4),
)
6 mislabeled molecules
Full dataset performance#
We now check how the model performs overall on the whole dataset. We also check which molecules are not properly labeled, as well as the distribution of predictions to get a sense of the model’s (un)certainty.
data_all = t.create_dataset_dict(add_edge_features=True)
full_dataset = t.MutagDataset(data_all)
Full ROC curve#
full_roc, full_ap, preds, ys = t.test(dataset, model, return_preds=True)
print(f"Full ROC-AUC: {full_roc:.4f}")
print(f"Full AP: {full_ap:.4f}")
# Plot the ROC curve
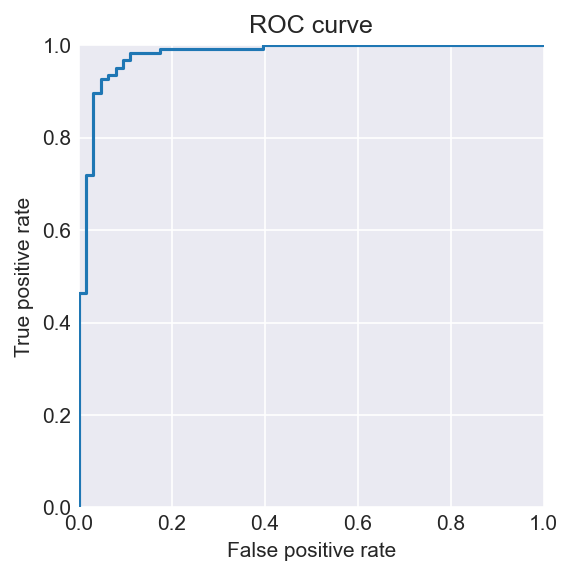
fig = t.plot_roc_curve(dataset, model)
preds = preds.cpu().detach().numpy()
ys = ys.cpu().detach().numpy()
print(
f"Number of correct positive predictions on test set: {np.sum((preds > 0.5) & (ys == 1))} out of {np.sum(ys == 1)}"
)
print(
f"Number of correct negative predictions on test set: {np.sum((preds < 0.5) & (ys == 0))} out of {np.sum(ys == 0)}"
)
Full ROC-AUC: 0.9792
Full AP: 0.9878
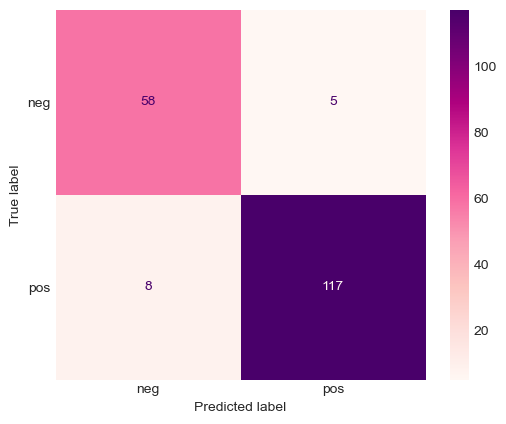
Number of correct positive predictions on test set: 117 out of 125
Number of correct negative predictions on test set: 58 out of 63
Predictions distribution#
utils.show_preds_distribution(preds, ys)
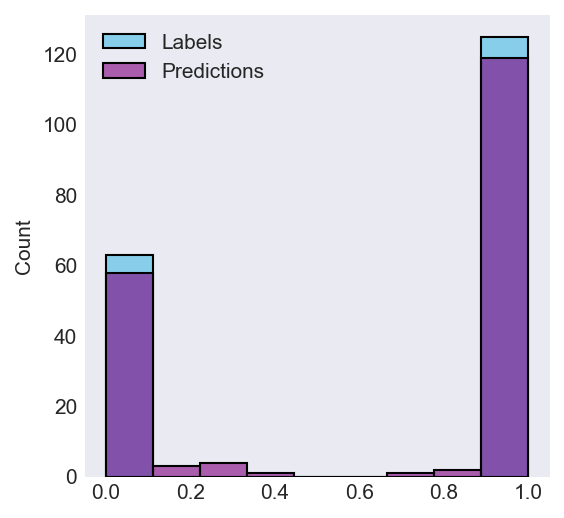
This plot shows the distribution of the labels and predictions;
predictions are overlayed on top of the labels,
showing whether they are missing or surnumerous.
The labels are 125 positive and 63 negative.
The predictions are 122 positive and 66 negative.
Confusion matrix#
utils.plot_confusion_matrix(preds, ys)
Check mislabelled molecules#
mislabeled = utils.find_mislabeled_molecules(preds, ys.astype(int))
print(f"{len(mislabeled)} mislabeled molecules")
mols = []
for id_mol in mislabeled:
mols.append(full_dataset[id_mol])
thresh_preds = np.where(preds > 0.5, 1, 0)[mislabeled]
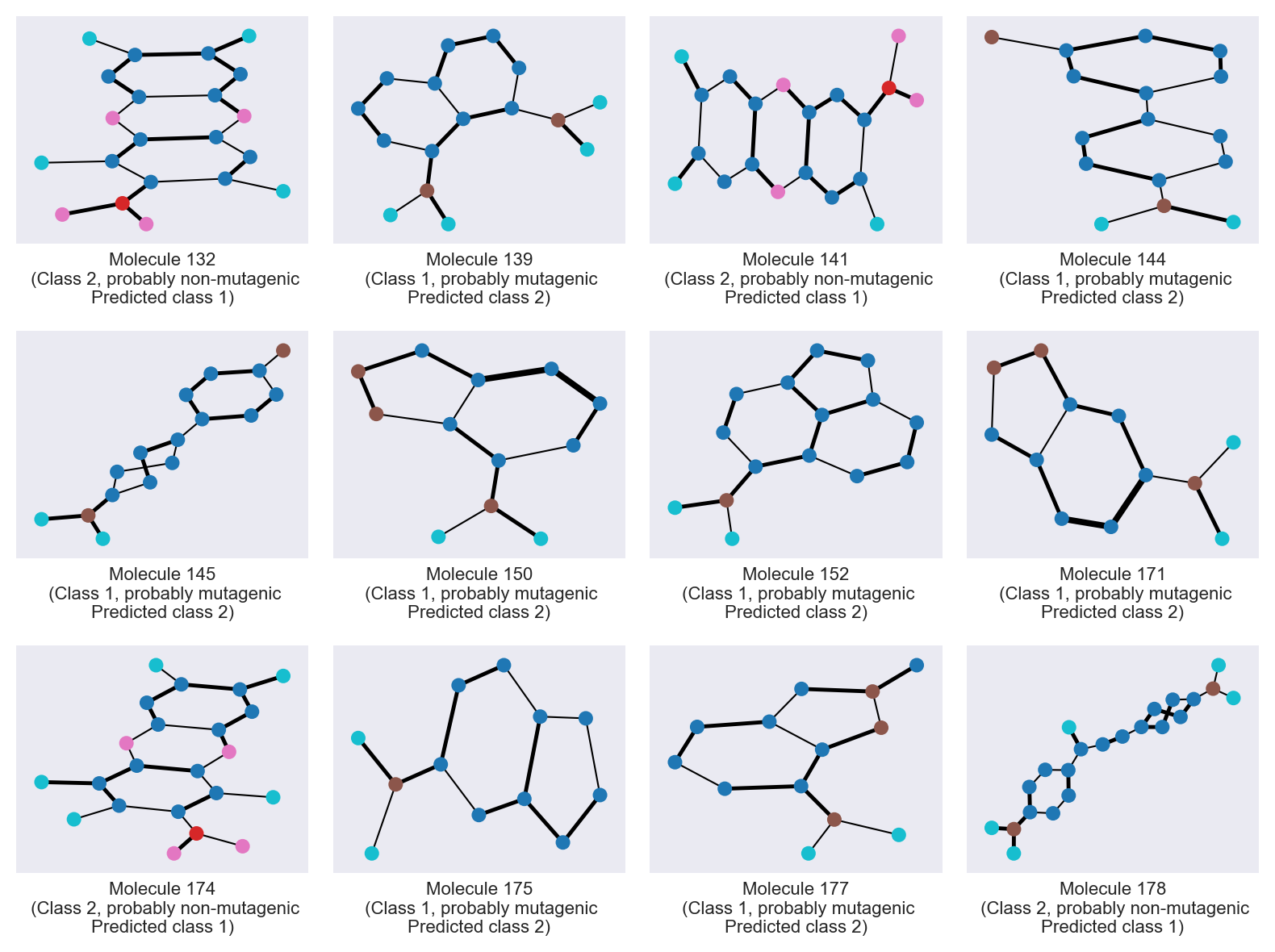
utils.draw_molecule_from_dict(
mols[:12],
preds=thresh_preds,
mol_ids=mislabeled,
n_cols=4,
n_rows=3,
figsize=(8, 6),
)
13 mislabeled molecules